
机器学习中偏差、方差的理解与总结
日期: 2020-05-08 分类: 个人收藏 573次阅读
一、理解偏差、方差
偏差(距离远近):描述的是预测值的期望与真实值之间的差距,偏差越大,越偏离真实数据
方差(是否聚集):预测值的方差,描述的是预测值的变化范围,离散程度,也就是离预测值期望值的距离,方差越大,数据的分布越分散,概念上理解比较抽象,下面我们通过下面一个例子来理解一下偏差和方差

如上图,我们假设一次射击就是一个机器学习模型对一个样本进行预测,射中红色靶心位置代表预测准确,偏离靶心越远代表预测误差越大。偏差则是衡量射击的蓝点离红圈的远近,射击位置即蓝点离红色靶心越近则偏差越小,蓝点离红色靶心越远则偏差越大;方差衡量的是射击时手是否稳即射击的位置蓝点是否聚集,蓝点越集中则方差越小,蓝点越分散则方差越大。
二、偏差、方差与模型范化能力
先给出结论:模型的泛化能力(泛化误差)是由偏差、方差与数据噪声之和,如下式: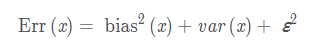
偏差度量的是学习算法预测误差和真实误差的偏离程度,即刻画学习算法本身的学习能力,方差度量同样大小的训练数据的变动所导致的学习性能的变化,即刻画数据扰动所造成的影响,噪声则表达了当前任务上任何学习算法所能到达的期望预测误差的下界,即刻画了学习问题本身的难度,因此泛化误差是由学习算法的能力、数据的充分性以及问题本身难度决定
学习算法刚训练时,训练不足欠拟合,此时偏差较大;当训练程度加深之后,训练数据的扰动也被算法学习到了,此时算法过拟合,方差过大,训练数据轻微扰动都会使得学习模型发生显著变化,因此我们得出结论:模型欠拟合时偏差过大,模型过拟合时方差过大。我们通过下面的例子来更形象的理解一下上面的描述的结论,看下图
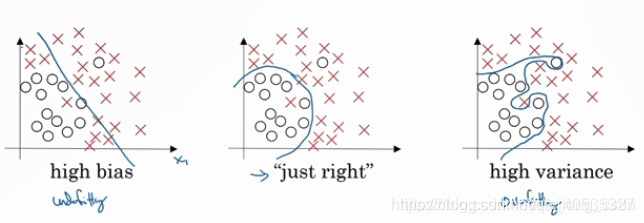
例如现在我们选择机器学习模型对图中数据做拟合,上左图使用直线对数据进行拟合,直线不能很好的分割数据,预测值将有大量分错,如红色的叉分到了蓝色的圈一类,此时模型偏差过大,模型欠拟合;再看上右图,模型过度拟合数据,将数据中的噪音点也都学到,此时数据的轻微波动将会导致预测结果的波动,方差过大,模型过拟合;自然上中图是我们认为比较好的拟合。
如上左图模型便是高偏差,但是方差小;上右图模型是高方差,但完全分割训练样本中所有数据因此偏差小;上中图便是比较理想的方差和偏差都比较小;那么有没有想像一下高方差同时又高偏差的模型是什么样子?如下图红色线展示的模型便是高方差同时高偏差
三、模型偏差高 or 方差高
在实际的应用中,如果一个模型对于测试集的预测不理想,那如何判断是由于高偏差导致还是高方差导致呢,这个判断对于后续模型优化至关重要。
参考方法:通过训练集误差和测试集误差来看高偏差 or 高方差
我们以猫狗分类模型为背景来看具体如何判断,对于猫狗分类首先我们有一个前提假设就是该数据本身能够达到很高的正确率,例如99%的正确率,看下面四种情况:
(1)训练集错误率:1%、测试集错误率:11% 低偏差高方差
(2)训练集错误率:15%、测试集错误率:16% 高偏差低方差
(3)训练集错误率:15%、测试集错误率:30% 高偏差高方差
(4)训练集错误率:0.5%、测试集错误率:1% 低偏差低方差
因此在实际工程中我们便可以通过比较训练集误差和测试集误差来看模型是由何种原因导致,然后采取相应的错误,下一节介绍如何优化模型
四、高偏差高方差时优化模型
1、高偏差(模型欠拟合)时模型优化方法
(1)添加特征数
当特征不足或者选取的特征与标签之间相关性不强时,模型容易出现欠拟合,通过挖掘上下文特征、ID类特征、组合特征等新特征,往往可以达到防止欠拟合的效果,在深度学习中,有很多模型可以帮助完成特征工程,如因子分解机、梯度提升决策树、Deep-crossing等都可以称为丰富特征的方法
(2)增加模型复杂度
模型过于简单则学习能力会差,通过增加模型的复杂度可以使得模型拥有更强的你和能力,例如在线性模型中添加高此项,在神经网络模型中增加隐层层数或增加隐层神经元个数
(3)延长训练时间
在决策树、神经网络中,通过增加训练时间可以增强模型的泛化能力,使得模型有足够的时间学习到数据的特征,可达到更好的效果
(4)减小正则化系数
正则化是用来方式过拟合的,但当模型出现欠拟合时则需要有针对的较小正则化系数,如xgboost算法
(5)集成学习方法Boosting
Boosting算法是将多个弱分类串联在一起,如Boosting算法训练过程中,我们计算弱分类器的错误和残差,作为下一个分类器的输入,这个过程本身就在不断减小损失函数,减小模型的偏差
(6)选用更合适的模型
有时候欠拟合的原因是因为模型选的不对,如非线性数据使用线性模型,拟合效果肯定不够好,因此有时需要考虑是否是模型使用的不合适
2、高方差(模型过拟合)时模型优化方法
(1)增加数据集
增加数据集是解决过拟合问题最有效的手段,因为更多的数据能够让模型学到更多更有效的特征,减小噪声的影响度。当然数据是很宝贵的,有时候并没有那么多数据可用或者获取代价太高,但我们也可以通过一定的规则来扩充训练数据,比如在图像分类问题上,可以通过图像的平移,旋转,缩放、模糊以及添加噪音等方式扩充数据集,在我的这篇文章中有介绍,更一步,可使用生成式对抗网络来合成大量的新数据
(2)降低模型的复杂度
数据集少时,模型复杂是过拟合的主要因素,适当降低模型复杂度可以避免模型拟合过多的采样噪音,例如在决策树算法中降低树深度、进行剪枝;在深度网络中减少网络层数、神经元个数等
(3)正则化防止过拟合
正则化思想:由于模型过拟合很大可能是因为训练模型过于复杂,因此在训练时,在对损失函数进行最小化的同时,我们要限定模型参数的数量,即加入正则项,即不是以为的去减小损失函数,同时还考虑模型的复杂程度
未加入正则项的模型损失函数:
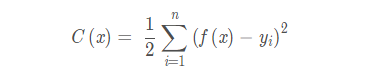
加入正则项L后损失函数:
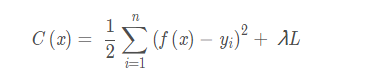
其中λ是正则项系数,是用来权衡正则项和损失函数之间权重,正则化有以下两种:
<1> L1正则化(L1范数):权重向量w的绝对值之和
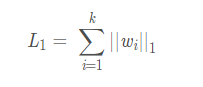
<2> L2正则化(L2范数):权重向量w的平方和,欧几里得范数
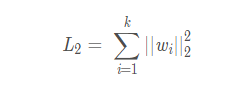
其中w代表模型的参数,k则代表了模型参数的个数
(4)集成学习方法Bagging
集成学习Bagging是把多个模型集成在一起,来降低单一模型的过拟合风险
(5)选用更合适的模型
在上诉方法都没有达到很好的效果时可以考虑选择使用其他模型处理数据
**
五、谈偏差和Boosting、方差和Bagging
**
上文在提到高偏差和高方差优化时使用集成学习方法,这小节再深入介绍一下为什么Bagging降低了模型方差,Boosting降低了模型的偏差
1、Bagging和方差
Bagging算法对数据重采样,然后在每个样本集训练出来的模型上取平均值
假设有n个随机变量,方差记为σ2,两两变量之间的相关性是ρ,则n个随机变量的均值的方差为:
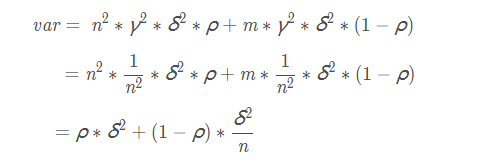
在随机变量完全独立的情况下,n个随机变量的方差是原来的1/n
Bagging算法对n个独立不相关的模型的预测结果取平均,方差是原来单个模型1/n,上述描述不严谨因为在实际问题中,模型不可能完全独立,但为了追求模型的独立性,Bagging的方法做了不同的改进,比如随机森林算法中,每次选取节点分裂属性时,会随机抽取一个属性子集,而不是从所有的属性中选最有属性,这就为了避免弱分类器之间过强的关联性,通过训练集的重采样也能够带来弱分类器之间的一定独立性,这样多个模型学习数据,不会因为一个模型学习到数据某个特殊特性而造成方差过高
2、Boosting和偏差
Boosting算法训练过程中,我们计算弱分类器的错误和残差,作为下一个分类器的输入,这个过程本身就在不断减小损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度
六、偏差方差平衡(Bias-Variance Tradeoff)
在实际的问题中噪音是数据自带的,没有办法优化,因此为了优化模型,降低模型的泛化误差,我们便从降低偏差和方差入手,但是方差和偏差存在权衡问题,即在优化一个时便会导致另一个升高,下图给出了泛化误差和偏差、方差的变化关系:
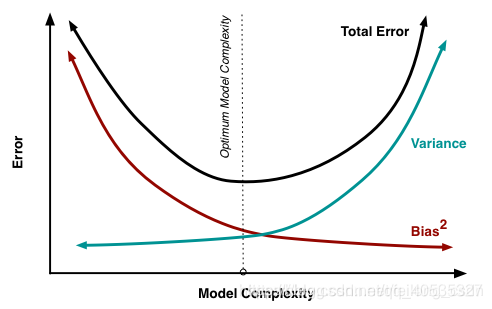
在训练不足时,模型的拟合能力不强,此时偏差主导着总体误差(泛化误差),随着训练程度的加深,模型的拟合能力已经很强,训练数据发生的噪音扰动也被模型学到,方差逐渐主导总体误差。因此我们在实际工程中需要找到一个合适的方式来权衡模型的偏差和方差?
————————————————
版权声明:本文为CSDN博主「feilong_csdn」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/feilong_csdn
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
标签:计算机 机器学习
上一篇: Shiro框架:认证和授权原理
精华推荐