
解构 StyleCLIP:文本驱动、按需设计,媲美人类 P 图师
日期: 2021-07-05 分类: 个人收藏 1303次阅读

来源:HyperAI超神经
本文约2200字,建议阅读5分钟 StyleCLIP 是一种新型「P 图法」,它结合了 StyleGAN 和 CLIP,可以仅依据文本描述,对图像进行修改和处理。
关键词:StyleGAN CLIP 机器视觉
提起 StyleGAN 大家都不陌生。这个由 NVIDIA 发布的新型生成对抗网络,借鉴风格迁移,可以快速生成大量的基于样式的新图像。
StyleGAN 学习能力强大,生成的图像也以假乱真,但是这种基于「看图」,进行学习和二次创作的方法,用的次数多了,也难免有些略显传统和保守。
来自希伯来大学、特拉维夫大学以及 Adobe 研究院的科研人员,创造性地将预训练 StyleGAN 生成器的生成能力,和 CLIP 的视觉语言能力结合起来,推出了一种全新的修改 StyleGAN 图像的方法--由文本驱动,你「写」什么样的要求,就生成什么样的图像。

用 StyleCLIP 进行文本驱动操作的示例
第一排为输入图像,第二排为操作结果
每列图像下方对应驱动图像改变的文本
StyleCLIP 到底是何方神圣
StyleCLIP 顾名思义,就是结合了 StyleGAN 和 CLIP。
StyleGAN 通过 Image Inversion 将图像表示成 Latent Code,进而通过编辑修改 Latent Code 控制图像风格。
CLIP 全称 Contrastive Language-Image Pretraining,是一个用 4 亿个图像-文字对,训练出来的神经网络,可依据给定的文字描述,输出最相关的图像。
科研人员在论文中,研究了 3 种结合 StyleGAN 和 CLIP 的方法:
1、 文本引导的潜在向量优化,其中 CLIP 模型被用作损失网络。
2、 训练 Latent Mapper,使潜在向量与特定文本一一对应。
3、 在 StyleGAN 的 StyleSpace 中,把文本描述映射到输入图像的全局方向 (Global Direction),控制图像操作强度以及分离程度。
相关工作
2.1 视觉及语言
联合表示 (Joint representations):有非常多的任务,都可以习得跨模式视觉和语言 (VL) 表示,如基于文本的图像检索、图像说明和视觉回答。随着 BERT 在各种语言任务中的成功,当下的 VL 方法通常使用 Transformers 来学习联合表示。
文本引导的图像生成和处理:训练一个符合条件的 GAN,从预训练编码器中获得文本嵌入,实现文本引导的图像生成。
2.2 Latent Space 图像处理
StyleGAN 的中间 Latent Space 已被证明,可以实现大量分解和有意义的图像处理操作,比如训练一个网络,把给定图像编码为被处理图像的嵌入向量,从而学习以端到端的方式进行图像处理。
图像处理均直接依据文本输入,用预先训练好的 CLIP 模型进行监督。由于 CLIP 是在数以亿计的文本-图像对儿上训练的,因此该方法是通用的,可以在众多领域中使用,不需要针对特定领域或特定处理进行数据标注。
3、StyleCLIP 文本驱动的图像处理
这项工作探索了文本驱动图像处理的三种方式,所有这些方式都结合了 StyleGAN 的生成能力和 CLIP 丰富的联合视觉-语言表示。
4、Latent 优化
利用 CLIP 指导图像处理的简单方法,是通过 direct latent 代码优化。
5、Latent Mapper
Latent 优化是通用的,因为它对所有源图像-文本描述对都进行了专门的优化。缺点是,编辑一张图像需要耗费数分钟的优化时间,而且该方法对其参数值有些敏感。
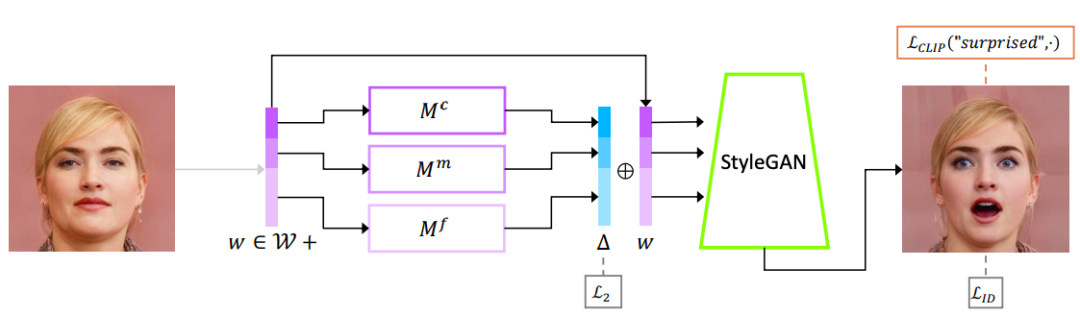
文本引导 Mapper 的架构
这里使用的文本提示是「惊讶」
不同的 StyleGAN 层,负责生成的图像的不同层次的细节
6、Global Directions
将文本提示映射到 StyleGAN 的 Style Space 中的单一的、全局的方向,该 Style Space 已被证实,比其他 Latent Space 更具有分离性。

由「grey hair」驱动的图像处理
适用于不同的操作强度和分离阈值
阅读完整论文:
https://arxiv.org/pdf/2103.17249v1.pdf
论文作者:来自以色列高校、专注 GAN
论文一作 Or Patashnik 是特拉维夫大学 CS 专业的一名研究生,主要从事图像生成和处理相关项目。
她对机器学习、计算机图形学和机器视觉都非常感兴趣,主要从事涉及图像生成和处理的项目,已发布数篇 StyleGAN 相关的论文。

论文作者 Or Patashnik(左)及 Zongze Wu(右)
论文的另一位作者 Zongze Wu,则是希伯来大学 Edmond & Lily Safra 脑科学中心的一名博士生,目前主要在 HUJI 机器视觉实验室,跟随 Adobe 研究所的 Dani Lischinski 和 Eli Shechtman 教授开展项目。
Zongze Wu 专注于计算机视觉相关课题,如生成对抗网络、图像处理、图像翻译等。
根据 Zongze Wu 的简历显示,2011-2016 年他就读于同济大学,专业是生物信息学 (Bioinformatics),毕业后 Zongze Wu 进入耶路撒冷希伯来大学的计算神经科学专业继续攻读博士。
结合 StyleGAN 与 CLIP 的三种方法详解
据 StyleCLIP 相关论文介绍,科研人员共研发出了 3 种方法,可以将 StyleGAN 和 CLIP 进行结合,这 3 种方法分别基于 Latent Optimization、Latent Mapper 以及 Global Direction。
1、基于 Latent Optimization
本教程主要介绍了基于迭代优化来做人脸编辑的内容,用户输入一段文本表述,得到和文字匹配的人脸编辑图像。
第一步 准备代码环境

第二步 参数设置

第三步 运行模型

第四步 可视化处理前后的图片


第五步 将优化过程存储为视频输出

完整 notebook 请访问:
https://openbayes.com/console/openbayes/containers/rlJisxxVhhD?path=%2Foptimization_playground.ipynb
2、基于 Latent Mapper
第一步 准备代码环境

第二步 设置参数

第三步 运行模型

第四步 可视化处理前后的图片


完整 notebook 请访问:
https://openbayes.com/console/openbayes/containers/rlJisxxVhhD?path=%2Fmapper_playground.ipynb
3、基于 Global Direction
本教程介绍了将文本信息映射到 StyleGAN 的隐空间中,再进一步修改图像的内容。用户可以输入一段文本表述,得到和文本非常匹配且具备良好特征解耦合性的人脸编辑图片。
第一步 准备代码环境

第二步 设置 StyleCLIP

第三步 设置 e4e

第四步 选择图片,使用 dlib 进行人脸对齐

第五步 将待编辑图片逆推到 StyleGAN 的隐空间中


第六步 输入文本表述

第七步 选择操纵强度 (alpha) 和解耦合阈值 (beta) 进行图片编辑


第八步 生成视频来可视化编辑的中间过程
完整 notebook 请访问:
https://openbayes.com/console/openbayes/containers/rlJisxxVhhD?path=%2Fglobal_direction.ipynb
关于 OpenBayes
OpenBayes 是国内领先的机器智能研究机构,提供算力容器、自动建模、自动调参等多项 AI 开发相关的基础服务。
同时 OpenBayes 还上线了数据集、教程、模型等众多主流公开资源,供开发者快速学习并创建理想的机器学习模型。
现在访问 openbayes.com 并注册
即可享用
600 分钟/周的 vGPU
以及 300 分钟/周 的 CPU 免费计算时
快行动起来,用 StyleCLIP 设计你想要的人脸吧!
完整教程传送门:
https://openbayes.com/console/openbayes/containers/rlJisxxVhhD
你也可点击阅读原文,访问完整教程。
参考:
https://arxiv.org/pdf/2103.17249v1.pdf
https://github.com/orpatashnik/StyleCLIP
编辑:王菁
校对:林亦霖

除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
上一篇: 轻量级实用PDF转换工具
下一篇: SQL用了两年多,分享2个最常用的小技巧
精华推荐