
日志文件分析溯源(Google蜘蛛)
日期: 2019-09-01 分类: 个人收藏 626次阅读
用记事本打开,常见的Google蜘蛛有两种。
一种是搜索引擎使用的Googlebot,它会访问制定的网页,收集该网页上的链接,而且会顺着这些链接找其他的网页。
还有一种叫做Mediabot,这种蜘蛛也是Google的,它的目的是抓取网页来匹配Google AdSense与相关内容的广告。
搜索googlebot,发现来自于210.185.192.212的get请求{210.185.192.212 - - [27/Sep/2018:18:15:24 +0800] “GET /home/goods/lists/cat/48.html HTTP/1.1” 200 140553 “http://210.5.56.14/home/goods/lists/cat/47.html” “x1cMozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)x1d”}
输入ip,得到key
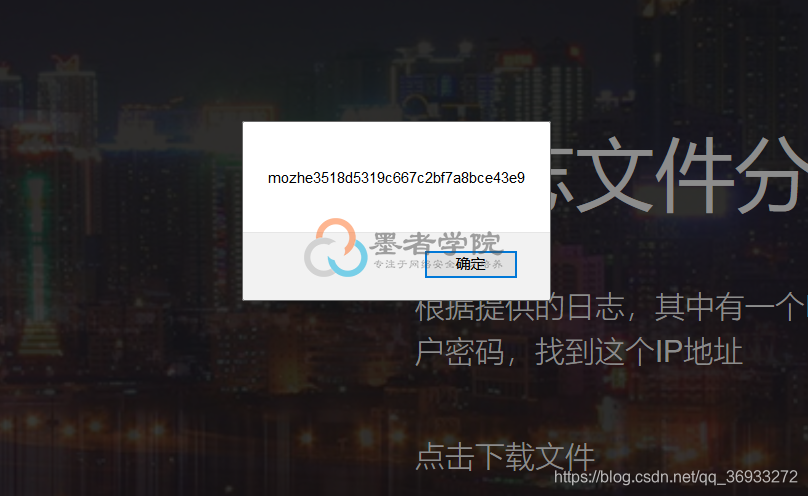
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
上一篇: 左耳听风 第四十三周
精华推荐