
使用华为轻量级网络GhostNet训练自己的数据
日期: 2021-06-21 分类: 个人收藏 993次阅读
前言
华为的GhostNet作为一款轻量型的网络,权重文件10M左右,但是网络性能确能超过Google发布的mobileNet, 今天就使用华为的GhostNet来做一个图像的二分类的应用。
1,运行环境
blas 1.0
ca-certificates 2021.1.19
certifi 2020.12.5
cudatoolkit 10.2.89
freetype 2.10.4
intel-openmp 2020.2
jpeg 9b
libpng 1.6.37
libtiff 4.1.0
libuv 1.40.0
lz4-c 1.9.3
mkl 2020.2
mkl-service 2.3.0
mkl_fft 1.2.1
mkl_random 1.1.1
msys2-conda-epoch 20160418
ninja 1.7.2
numpy 1.19.2
numpy-base 1.19.2
olefile 0.46
openssl 1.1.1j
pillow 8.1.0
pip 21.0.1
python 3.8.5
pytorch 1.7.1
setuptools 52.0.0
six 1.15.0
sqlite 3.33.0
tk 8.6.10
torchaudio 0.7.2
torchvision 0.8.2
typing_extensions 3.7.4.3
vc 14.2
vs2015_runtime 14.27.29016
wheel 0.36.2
wincertstore 0.2
xz 5.2.5
- 源码地址 : GhostNet
2,模型训练
由于GitHub上没有给出训练的demo,所以需要自己编写训练的脚本程序。结合ghostnet.py,训练的程序如下:
import os
import time
import argparse
import logging
import numpy as np
from collections import OrderedDict
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from ghostnet import ghostnet
from sklearn.metrics import accuracy_score
def accuracy(y_pred,y_true):
y_pred_cls = torch.argmax(nn.Softmax(dim=1)(y_pred),dim=1).data
return accuracy_score(y_true,y_pred_cls)
def train(valdir):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
loader = torch.utils.data.DataLoader(
datasets.ImageFolder(valdir, transforms.Compose([
transforms.Resize(160),
transforms.CenterCrop(160),
transforms.ToTensor(),
normalize,
])),
batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True)
model = ghostnet(num_classes=args.num_classes, width=args.width, dropout=args.dropout)
model.optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
model.loss_func = nn.CrossEntropyLoss()
model.metric_func = accuracy
model.metric_name = "accuracy"
epochs = 1
log_step_freq = 100
for epoch in range(1, epochs + 1):
# 1,训练循环-------------------------------------------------
model.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features, labels) in enumerate(loader, 1):
# 梯度清零
model.optimizer.zero_grad()
# 正向传播求损失
predictions = model(features)
loss = model.loss_func(predictions, labels)
metric = model.metric_func(predictions, labels)
# 反向传播求梯度
loss.backward()
model.optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
print(("[step = %d] loss: %.3f, " + model.metric_name + ": %.3f") %
(step, loss_sum / step, metric_sum / step))
torch.save(model.state_dict(), './models//model.pt')
def valid_step(model, features, labels):
# 预测模式,dropout层不发生作用
model.eval()
predictions = model(features)
loss = model.loss_func(predictions, labels)
metric = model.metric_func(predictions, labels)
return loss.item(), metric.item()
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='PyTorch ImageNet Inference')
parser.add_argument('--data', metavar='DIR', default='./cache/data/imagenet/',
help='path to dataset')
parser.add_argument('--output_dir', metavar='DIR', default='./cache/models/',
help='path to output files')
parser.add_argument('-j', '--workers', default=4, type=int, metavar='N',
help='number of data loading workers (default: 2)')
parser.add_argument('-b', '--batch-size', default=10, type=int,
metavar='N', help='mini-batch size (default: 1)')
parser.add_argument('--num-classes', type=int, default=2,
help='Number classes in dataset')
parser.add_argument('--width', type=float, default=1.0,
help='Width ratio (default: 1.0)')
parser.add_argument('--dropout', type=float, default=0.2, metavar='PCT',
help='Dropout rate (default: 0.2)')
parser.add_argument('--num-gpu', type=int, default=1,
help='Number of GPUS to use')
args = parser.parse_args()
valdir = os.path.join(args.data, 'val1')
train(valdir)
注:
由于使用的是Pytorch训练ghostnet模型所以数据集必须要按照Pytorch要求的方式存放,即每一类都必须放在一个子文件夹里,如下所示:
注: 由于是做二分类,源码中的全连接层的输入是1280维,如果做二分类的话应该是不需要这么多的特征的,所以这里训练时将全连接层的输入从1280维改成了100维。

训练的模型大小才11M多:
3,测试
测试直接使用源码中validate.py即可,这里也需要做一下更改,因为只做二分类,只有top1正确率,没有top5正确率,所以关于计算正确率也需要稍微做一下修改。运行测试的效果如下:
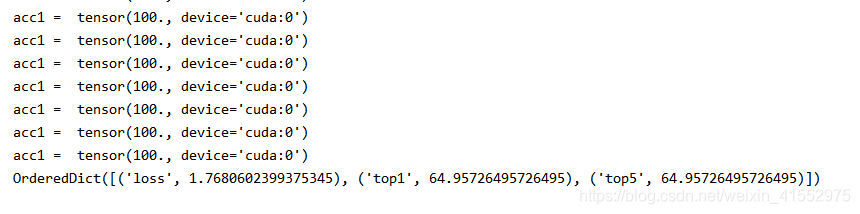
这里只有64.9的正确率的原因是训练的样本太少,通过数据增强总共约4万张图片进行训练,实际的源图为4000张左右,加上为了测试训练的模型的泛化性能,测试的数据集其实是偏中性一点,也就是说既有正例的特征又有反例的特征,所以才会导致正确率较低。如果调整训练数据,正确率应该会大幅上升,拿正例未经训练的样本测试,正确率能够达到98%以上。
4,总结:
ghostnet的分类性能还是比较优越的,且模型十分小巧,如果能部署到移动端还是很不错的。- 但是通过
pytorch训练pt模型然后转pb模型部署,问题还是比较多
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐