
Scala中的类和构造器
日期: 2018-01-26 分类: 个人收藏 467次阅读
Scala中的类
摘要
网络上很多资料讲得不清不楚的,有些甚至是片面的错误的,看语言应该是直接用翻译器将英文翻译成中文。所以依照着网上的一些说法和自己的实验重新将一些概念和定义讲解一些。
scala编译器会自动为类中的字段添加getter方法和setter方法
可以自定义getter/setter方法来替换掉编译器自动产生的方法
用@BeanProperty注解来生成JavaBeans的getXxx/setXxx()方法
每个类都有一个主要的构造器,这个构造器不是单独声明的构造函数,而是和类定义交织在一起。它的参数直接成为类的字段。主构造器执行类声明中所有的语句。
辅助构造器是可选的,它们叫做this。
简单类和无参方法
简单类
Scala类最简单的形式看上去和Java或c+++的很相似:
class Counter {
private var value = 0 // 你必须初始化字段
def increment() { value += 1 } // 方法默认是公有的
def current() = value
}
val myCounter = new Counter // 或new Counter()
myCounter.increment()
println(myCounter.current) // 1无参方法
调用无参方法比如current时,你可以写上圆括号,也可以不写:
myCounter.current
myCounter.current() 应该用哪一种形式呢,我们认为对于改值器方法,即改变对象状态的方法使用(),而对于取值器方法,它不会改变对象状态的方法,所以去掉()。这也是我们在示例中的做法:
myCounter.increment() //对改值器使用()
println(myCounter.current) //对取值器不使用()你可以通过以不带()的方式声明current来强制这种风格:
class Counter {
def current = value //定义中不带()
}这样一来类的使用者就必须用myComter.current,不带圆括号。
访问级别
Java
| 修饰符 | Class | Package | Subclass | World |
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| no modifier | Y | Y | N | N |
| private | Y | N | N | N |
Java的四种访问级别在上面罗列了。成员变量、成员函数什么的都是非常常见的使用方法,因为资料非常多,也就不详细说明了。
唯一让我觉得有趣的是
private class的问题。虽然不知道在OOP中会不会有这样的设计,但是我突然就想到了,便研究了一下。
对于一个.java的文件,我们对于文件的命名和文件中类的命名有如下的规则:
- Java保存的文件名必须与类名一致;
- 一个Java文件中只能有一个顶层public类;
- 一个Java文件中不能有一个顶层private类;
- 如果文件中不止一个类,文件名必须与public类名一致;
- 如果文件中不止一个类,而且没有public类,文件名可与任一类名一致。
所谓的顶层类(外部类)指的是可以直接通过包来访问的。
而private类是不能作为外部类的,因为没有任何其他东西能够访问它。
private class SomePrivateClass{ ... }会导致报错。
使用的方式是在外面嵌套一个顶层类
public class OuterClass {
private class InnerClass {
...
}
...
}Scala
在Scala中,没有类似Java中那样public。它的默认修饰符,即no modifier就是相当于public。
| 修饰符 | Class | Companion | Subclass | Package | World |
| no modifier | Y | Y | Y | Y | Y |
| protected | Y | Y | Y | N ∗ ∗ | N |
| private | Y | Y | N | N ∗ ∗ | N |
*: 表示顶层的protected和private成员是包内可见的。不是顶层的是不可见的。
这个顶层private的包内可见性是我对这个问题产生兴趣的关键。
package tprivate
import scala.beans.BeanProperty
private class Student { // 这样定义是可以的
@BeanProperty
var age = 20
private var name = "clow"
def getName: String = this.name
def setName(value: String) {
this.name = value
}
}
object Demo {
def main(args: Array[String]): Unit = {
var instant = new Student //这样是可以访问的,或者在同一个包的其他文件也是可以访问的
println(instant.getAge())
}
}package test
import tprivate.Student
object Testprivate {
def main(args: Array[String]): Unit = {
var instant = new Student // 这样是无法访问的
println(instant.getAge())
}
}Scala中的字段属性
Scala对每个字端都会自动提供get和set方法。
例如,我们定义一个公有字段:
class Person {
var age = 0
}Scala编译器生成能够在JVM上运行的类,其中会有一个私有的age字段以及相应的公有getter方法和setter方法。
若是我们将age声明为private。Scala编译器产生的getter和setter方法也是私有的。(关于这一点网上很多的说法都是不严谨的。)
Scala中的getter和setter
在Scala中,getter和setter分别叫做age和age_。
println (fred.age) // 将调用方fred.age()
fred.age= 21 // 将调用fred.age_=(21)如果想亲眼看到这些方法,可以编译Person类,然后用java反编译器编译会.java文件,或者用javap查看字节码:
scalac Person.scala
javap -private Person输出是
Compiled from "Person.scala"
public class Person extends java.lang.Object implements scala.ScalaObject {
private int age;
public int age()
public void age_$eq(int)
public Person()
}正如你看到的那样,编译器创建了age和age_ eq方法。=号被翻译成 e q 方 法 。 = 号 被 翻 译 成 eq,是因为JVM不允许在方法名中出现=。
所以在使用age的时候,其实不是像C++那样直接访问变量,而是调用了相应的无参数方法。
Scala中的自定义getter和setter
在任何时候你都可以自己重新定义getter和setter方法。例如:
class Person {
private var privateAge =0 // 变成私有并改名
def age = privateAge
def age_= (newValue: Int) {
if (newValue > privateAge)
privateAge=newValue // 不能变年轻
}
}你的类的使用者仍然可以访问fred.age,但现在Fred不能变年轻了:
fred.age = 30
fred.age = 21
println(fred.age) // 30Bertrand Meyer提出了统一访问原则(Uniform access principle),内容如下:”某个模块提供的所有服务都应该能通过统一的表示法访问到,至于它们是通过存储还是通过计算来实现的,从访问方式上应无从获知”。
在Scala中,fred.age的调用者并不知道age是通过字段还是通过方法来实现的。而C++就不是这样,成员函数和成员变量的访问是不同的。
还需注意的是:Scala对每个字段生成getter和setter方法听上去有些恐怖,不过你可以控制这个过程如下:
- 如果字段是私有的,则getter和setter方法也是私有的
- 如果字段是val,则只有getter方法被生成
- 如果你不需要任何getter或setter,可以将字段声明为
private[this]
这几点在设计的时候非常重要,网络上关于这几点讲解得有些不太明确。
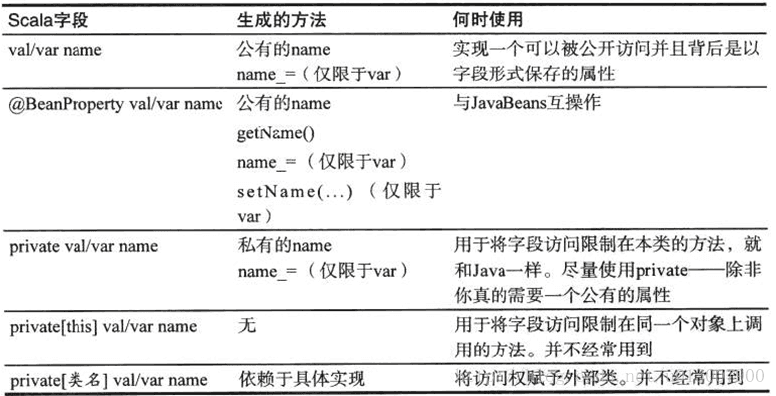
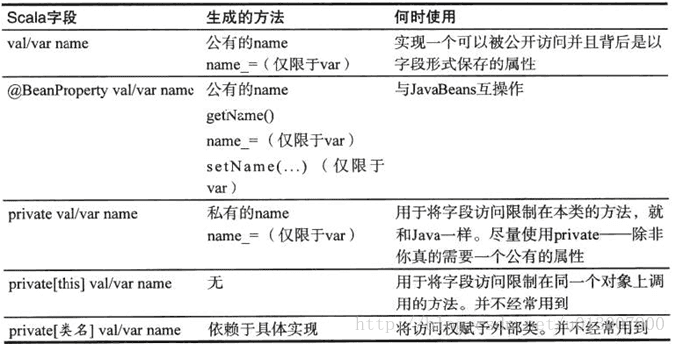
Bean属性
正如你在前面所看到的,Scala对于你定义的字段提供了getter和setter方法。不过,这些方法的名称并不是Java工具所预期的,可参见JavaBeans规范。
把Java属性定义为一对getFoo/setFoo方法或者对于只读属性而言单个getFoo方法。许多Java工具都依赖这样的命名习惯。当你将Scala字段标注为@BeanProperty时,这样的方法会自动生成。例如:
import scala.reflect.BeanProperty
class Person {
@BeanProperty var name: String=_
}这种方式只适用于非私有变量,将会生成四个方法:
- name:String
- name_=(newValue: Strmg):Unit
- getName():String
- setName(newValue: String): Unit
下表显示了在各种情况下哪些方法会被生成:
如果你以主构造器参数的方式定义了某字段,并且你需要JavaBeans版的getter和setter方法,像如下这样给构造器参数加上注解即可:
class Person(@BeanProperty var name: String) {
...
}主构造器(构造函数)
组成
Scala类的主要构造函数是以下的组合:
- 构造函数参数
- 在类的主体中调用的方法
- 语句和表达式在类的主体中执行
// scala
class Person(var firstName: String, var lastName: String) { // primary constructor
println("the constructor begins")
// some class fields
private val HOME = System.getProperty("user.home")
var age = 0
// some methods
override def toString = s"$firstName $lastName is $age years old"
def printHome { println(s"HOME = $HOME") }
def printFullName { println(this) } // uses toString
// some expression
printHome
printFullName
println("still in the constructor")
}
object Demo {
def main(args: Array[String]): Unit = {
var instant = new Person("jing", "su")
}
}
/*
the constructor begins
HOME = C:\Users\lenovo
jing su is 0 years old
still in the constructor
*/在Scala中,每个类都有主构造器,不需要单独声明构造函数,不以this方法定义,主构造器与类的定义或者字段声明交织在一起。当你阅读一个Scala类时,你需要将它们分开理解,一个是类的定义,一个是构造函数的定义。
主构造器的参数直接放置在类名之后,并直接被编译成字段,其值被初始化成构造时传入的参数。
在本例中lastname和firstname成为Person类的字段。
这样的构造器相比于Java代码,节约了极大的工作量。
// java
public class Person {
private String firstName;
private String lastName;
private final String HOME = System.getProperty("user.home");
private int age;
public Person (String firstName, String lastName) {
super ();
this.firstName = firstName;
this.lastName = lastName;
System.out.println("the constructor begins");
age = 0;
printHome();
printFullName();
System.out.println("still in the constructor");
}
public String firstName() {
return firstName;
}
public String lastName() {
return lastName;
}
public int age() {
return age;
}
public void firstName_$eq(String firstName) {
this.firstName = firstName;
}
public void lastName_$eq(String lastName) {
this.lastName = lastName;
}
public void age_$eq(int age) {
this.age = age;
}
public String toString() {
return firstName + " " + lastName + " is " + age + " years old";
}
public void printHome() {
System.out.println(HOME);
}
public void printFullName() {
System.out.println(this);
}
}无参主构造器
如果类名之后没有参数,则该类具备一个无参主构造器。这样一个构造器仅仅是简单地执行类体中的所有语句而已。你通常可以通过在主构造器中使用默认参数来避免过多地使用辅助构造器。例如:
class Person(val firstName: String = "", val lastName: String = "") 主构造器参数
主构造器的参数可以采用下表中列出的任意形态
例如:
class Person (val firstName: String, privite var lastName: String)这段代码将声明并初始化如下字段:
val firstName: String
private var lastName: String构造参数也可以是普通的方法参数,不带val或var。这样的参数是不可变得,而且不带修饰符的参数和private val还是有区别的。
他们的存在方式取决于它们在类中如何被使用。
class Person(private val firstName: String, lastName: String)对于如上的类,将之编译并用javap -v Person查看Java字段之后,我们就可以发现仅仅只有firstName字段。而lastName仅仅是构造器参数,在构造完成之后,就会被垃圾回收。
如果不带val或var的参数至少被一个方法所使用,它将被编译器自动升格为字段。例如:
class Person(private val firstName: String, lastName: String) {
def fullName = firstName + " " + lastName
}
// if we'd defined fullName as a val instead of a def,
// it'd only have one field如果我们将firstName声明为对象私有(object-private),而不是类私有(class-private),那么它和无修饰符的参数作用类似。具体可以查阅参考文献[5]的5.2章节。
class Person(private[this] val firstName: String, lastName: String)
class Person(private[this] var firstName: String, lastName: String)
主构造器参数生成字段
下表总结了不同类型的主构造器参数对应会生成的字段和方法:

如果主构造器的表示法让你困惑,你不需要使用它。你只要按照常规的做法提供一个或多个辅助构造器即可,不过要记得调用this(),如果你不和其他辅助构造器串接的话。
话虽如此,许多程序员还是喜欢主构造器这种精简的写法。Martin Odersky建议这样来看待主构造器:在Scala中,类也接受参数,就像方法一样。当你把主构造器的参数看做是类参数时,不带val或var的参数就变得易于理解了,这样的参数的作用域涵盖了整个类。因此,你可以在方法中使用它们。而一旦你这样做了,编译器就自动帮你将它保存为字段。
辅助构造器
除了主构造器之外,类还可以有任意多的辅助构造器(auxiliary constructor)。
我之所以后讨论辅助构造器,是因为主构造器更重要也更难理解。当明确地理解了Scala主构造器和Java、C++等构造函数的区别后,就能更加轻松地理解辅助构造器,因为辅助构造器同Java或C++的构造函数十分相似,只有两处不同。
- 辅助构造器的名称为this。而在Java或C++中,构造器的名称和类名相同。
- 每一个辅助构造器都必须以一个对先前已定义的其他辅助构造器或主构造器的调用开始
这里有一个带有两个辅助构造器的类。
和Java、C++一一样,类如果没有显式定义主构造器则自动拥有一个无参的主构造器即可。你可以以三种方式构建对象:
class Person {
private var name = ""
private var age = 0
def this(name: String) { // 辅助构造器1
this() // 调用主构造器
this.name = name
}
def this (name: String, age: Int) { // 辅助构造器2
this(name) //调用辅助构造器1
this.age = age
}
}
object Testprivate {
def main(args: Array[String]): Unit = {
var instant1 = new Person //主构造器
var instant2 = new Person("sujing") //辅助构造器1
var instant3 = new Person("sujing", 3) //辅助构造器2
}
}嵌套类
Scala内嵌类
在Scala中,你几乎可以在任何语法结构中内嵌任何语法结构。你可以在函数中定义函数,在类中定义类。以下代码是在类中定义类的一个示例:
class Network {
private val members = new ArrayBuffer[Member]
def join(name: String) = {
val m = new Member(name)
members += m
m
}
class Member(val name: String) {
val contacts = new ArrayBuffer[Member]
}
}在Scala中,每个实例都有它自己的Member类,就和它们有自己的members字段一样,考虑有如下两个网络:
val chatter = new Network
val myFace = new Network也就是说,chatter.Member和myFace.Member是不同的两个类。
这和Java不同,在Java中内部类从属于外部类。Scala采用的方式更符合常规,举例来说,要构建一个新的内部对象,你只需要简单的new这个类名:new chatter.Member。而在Java中,你需要使用一个特殊语法:chatter.new Member()。拿我们的网络示例来讲,你可以在各自的网络中添加成员,但不能跨网添加成员:
val fred = chatter.join("Fred")
val wilma = chatter.join("Wilma")
fred.contacts += wilma //OK
val barney = myFace.join("Barney") // 类型为myFace .Member
fred.contacts += barney // 不可以这样做,不能将一个myFace.Member添加到chatter.Member元素缓冲当中Scala内嵌类访问
对于社交网络而言,这样的行为是讲得通的。如果你不希望是这个效果,有两种解决方式。
首先,你可以将Member类移到别处,一个不错的位置是Network的伴生对象。
object Network {
class Member (val name: String) {
val contacts=new ArrayBuffer[Member]
}
}
class Network {
private val members = new ArrayBuffer[Network.Member]
}
或者,你也可以使用类型投影Network#Member,其含义是“任何Network的Member”。例如:
class Network {
class Member (val name: String) {
val contacts = new ArrayBuffer[Network#Member]
}
}如果你只想在某些地方,而不是所有地方,利用这个细粒度的”每个对象有自己的内部类”的特性,则可以考虑使用类型投影。
内嵌类访问外部类
在内嵌类中,你可以通过外部类.this的方式来访问外部类的this引用,就像Java那样。
如果需要,也可以用如下语法建立一个指向该引用的别名:
class Network(val name: String){ outer=>
class Member (val name: String) {
def dascription=name+"inside"+outer.name
}
}class Network { outer=>语法使得outer变量指向Network.this。对这个变量,你可以用任何合法的名称。self这个名称很常见,但用在嵌套类中可能会引发歧义。
参考资料
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐