
关于卷积神经网络细节的深入理解
日期: 2020-03-25 分类: 个人收藏 595次阅读
关于卷积神经网络细节的深入理解
文章目录
Ⅰ.关于softmax,Cross-Entropy Loss,Hinge Loss,L2正则化基本概念的深入理解:
1.Softmax:
通常,我们希望获得所有类别标签的概率分布。 因此,我们通过Softmax函数将得分函数f的结果映射到介于0和1之间的区间。
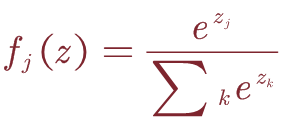
2.Cross-Entropy Loss:
令(xi,yi)为一对训练样本,其中xi∈R^D为训练数据,yi∈RK为一个one-hot向量,除其真实类索引为1外,全零。 假设预测 y ^ i {\hat{y}}_i y^i∈RK是在Softmax之后计算的,则交叉熵损失为:
这里举个小例子:x输入为img,经过softmax之后得到不同的预测结果: y ^ i {\hat{y}}_i y^i和 y ^ i {\hat{y}}_i y^i的预测值分别为0.1,0.9;而这里的1,2分别代表猫和狗2个类别。那么此时的L1=-1•log(0.1),而L2=-1•log(0.9),L1>L2,所以这张图片更像狗而不是猫。理解:但是如果这张图片的标签是猫的话,我们就要不断训练前面的卷积层参数,使最终的预测分类更接近于猫。**
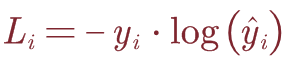
3.Hinge Loss:
注意,交叉熵损失的指数计算是相对复杂的,而有时我们不需要将预测结果映射到概率区间上。 因此,hinge Loss 的损失函数为:
j是其他类别的索引,yi是正确类别的索引。当f(xi-W)yi大于所有的f(xi,W)j+△时,损失值为0;这里的△是阈值,通过阈值判定分类正确与错误之间的界限。理解:Li含义是该输入的xi在其他类的得分大于正确分类的得分的累加作为损失值。
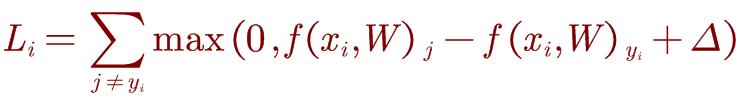
4.L2 norm:
正则化是防止模型学习过度拟合的常用技术。 最常见的正规化惩罚是L2范数,它通过对所有参数进行逐元素二次惩罚来阻止较大的权重:
k,d作为W权重矩阵的索引。
关于L2范数,以及正则化损失的理解:
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
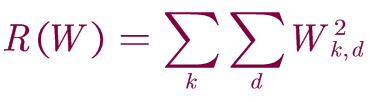
上一篇: jvm垃圾回收机制
下一篇: 【时间序列】ARIMA模型
精华推荐