
用SQL进行集合运算
日期: 2020-11-28 分类: 个人收藏 662次阅读
集合论是SQL语言的根基——因为它的这个特性,SQL也被称为面向集合语言
顾名思义,集合运算符的参数是集合,从数据库实现层面上来说就是表或者视图,集合运算有以下几个注意事项:
-
SQL能操作具有重复行的集合,可以通过可选项ALL来支持
一般的集合论是不允许集合里存在重复元素的,因此集合{1,1,2,3,3,3}和集合{1,2,3}被视为相同的集合。但是关系数据库里的表允许存在重复的行,称为多重集合
集合运算符为了排除掉重复行,默认地会发生排序,而加上可选项ALL之后,就不会再排序,所以性能会有提升。 这是非常有效的用于优化查询性能的方法,所以如果不关心结果是否存在重复行,或者确定结果里不会产生重复行,加上可选项ALL会更好
-
集合运算符有优先级
标准SQL规定,INTERSECT比UNION和EXCEPT优先级更高。因此,当同时使用UNION和INTERSECT,又想让UNION优先执行时,必须使用括号明确地指定运算顺序
-
各个DBMS提供商在集合运算的实现程度上参差不齐
-
除法运算没有标准定义
比较表和表:检查集合相等性
-- 假设事先已经确认了tbl_A和tbl_B的行数是一样的,可采用以下方法判定:
SELECT COUNT(*) AS row_cnt
FROM (SELECT *
FROM tbl_A
UNION
SELECT *
FROM tbl_B) TMP;
对于任意的表S,均有 S UNION S = S,这是UNION的一个非常重要的性质,在数学上我们称之为幂等性(indempotency)
-- 除了UNION之外,另一个具有幂等性的运算符就是INTERSECT
-- 两张表相等时返回“相等”,否则返回“不相等”
SELECT CASE WHEN COUNT(*) = 0
THEN '相等'
ELSE '不相等' END AS result
FROM ((SELECT * FROM tbl_A
UNION
SELECT * FROM tbl_B)
EXCEPT
(SELECT * FROM tbl_A
INTERSECT
SELECT * FROM tbl_B)) TMP;
-- 注意:MySQL中还无法使用INTERSECT和EXCEPT
用差集实现关系除法运算
SQL中还没有能直接进行关系除法运算的运算符,因此,为了进行除法运算,必须自己实现。方法比较多,其中具有代表性的是以下三个:
- 嵌套使用NOT EXISTS
- 使用HAVING子句转换成一对一关系
- 把除法变成减法
下面主要介绍一下方法3

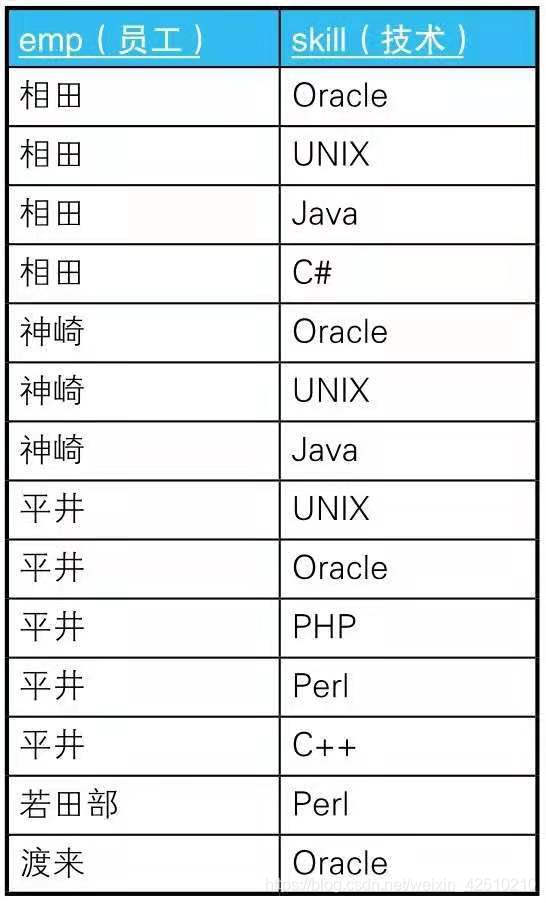
-- 用求差集的方法进行关系除法运算(有余数)
SELECT DISTINCT emp
FROM EmpSkills ES1
WHERE NOT EXISTS
(SELECT skill
FROM Skills
EXCEPT
SELECT skill
FROM EmpSkills ES2
WHERE ES1.emp = ES2.emp);
寻找相等的子集
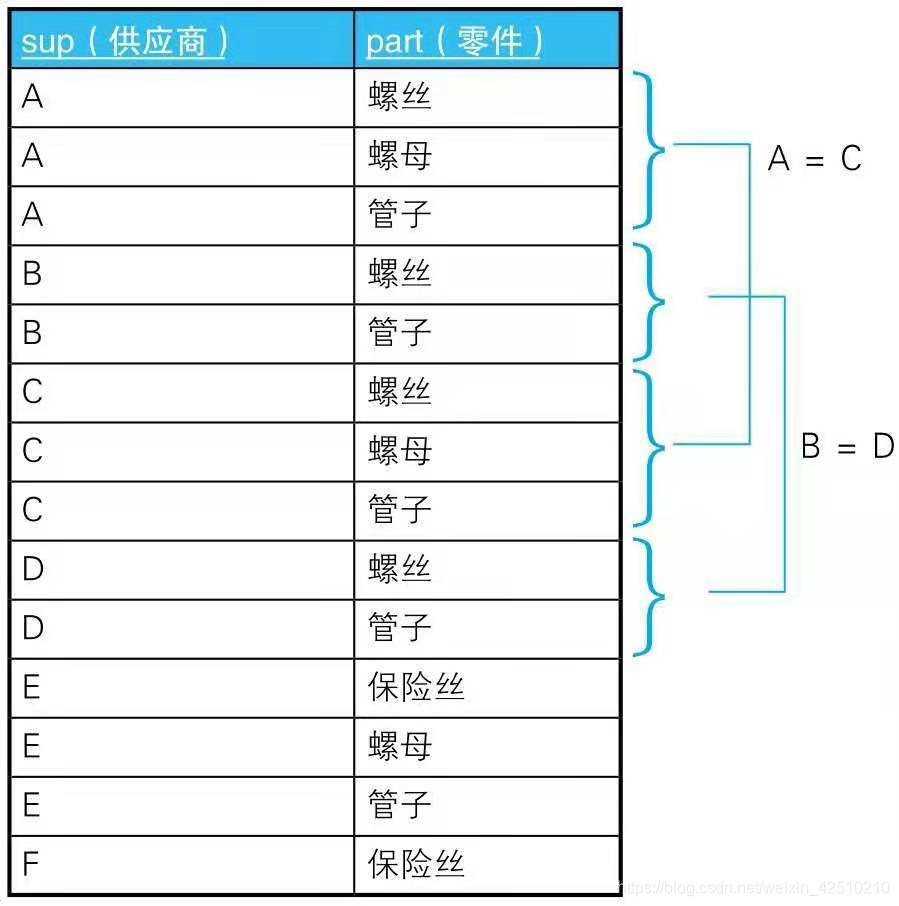
-- 生成供应商的全部集合(非等值连接 + 聚合(为了去除重复))
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup
GROUP BY SP1.sup, SP2.sup;
SELECT SP1.sup AS s1, SP2.sup AS s2
FROM SupParts SP1, SupParts SP2
WHERE SP1.sup < SP2.sup
AND SP1.part = SP2.part -- 条件1:经营同种类型的零件
GROUP BY SP1.sup, SP2.sup
HAVING COUNT(*) = (SELECT COUNT(*) -- 条件2:经营的零件种类数相同
FROM SupParts SP3
WHERE SP3.sup = SP1.sup)
AND COUNT(*) = (SELECT COUNT(*)
FROM SupParts SP4
WHERE SP4.sup = SP2.sup);
用于删除重复行的高效SQL
-- 没有主键
-- 使用关联子查询
DELETE FROM Products
WHERE rowid < (SELECT MAX(P2.rowid)
FROM Products P2
WHERE Products.name = P2.name
AND Products.price = P2.price);
-- 用于删除重复行的高效SQL语句(1):通过EXCEPT求补集
DELETE FROM Products
WHERE rowid IN (SELECT rowid
FROM Products
EXCEPT
SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
-- 删除重复行的高效SQL语句(2):通过NOT IN求补集
DELETE FROM Products
WHERE rowid NOT IN (SELECT MAX(rowid)
FROM Products
GROUP BY name, price)
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
标签:sql 数据库
上一篇: 这份数据清洗checklist,让开发过程更加高效
下一篇: HAVING子句的力量
精华推荐