
使用requests库实现豆瓣Top250电影信息爬取+简单使用多线程提高效率
日期: 2020-11-06 分类: 个人收藏 619次阅读
第一部分:直接获取!!!
1.目标URL:https://movie.douban.com/top250!
2.python中利用requests+etree+re+json+fake_useragent模块实现:(代码没有任何问题,可以随拿随用!)
import requests
from lxml import etree
import re
import json
from fake_useragent import UserAgent
def films(num):
page_url="https://movie.douban.com/top250?start={}&filter=".format(num)
# 添加UA以防最基础的UA反爬!
headers={
"User-Agent": UserAgent().random
}
res=requests.get(page_url,headers=headers)
# 解析数据
html=etree.HTML(res.text)
# 定义空字典:存放处理过后的目标数据!
film_info = {}
films_info = html.xpath("//div[@class='info']")
# 一次打开文件,写完全部目标数据后再进行关闭文件,节省资源!
with open("films_info.json", 'a',encoding='utf-8') as f:
for film_one in films_info:
# 电影名称
film_name = film_one.xpath("./div/a/span[1]/text()")[0]
# 电影导演+主演 注意:电影导演和主演在网页中是放在同一个p标签下,所以要进行特殊处理!
film_author_actor = film_one.xpath("./div[2]/p/text()")[0].strip()
# 电影导演 反复观察可知:if中的为电影导演和主演靠三个\xa0,即空格分开,电影导演在前! else中的为电影信息只有导演,连主演的主都没的!
if "主" in film_author_actor:
film_author_test = re.findall(': (.*)\\xa0',film_author_actor)[0].strip()
film_author = re.sub('\\xa0','',film_author_test)
else:
film_author_test = re.findall(': (.*)',film_author_actor)[0]
film_author = re.sub('\\xa0', '', film_author_test)
# 电影主演 注意:有个别电影没有主演信息!(仅有一个主字或者主演两个字的!通过if筛选掉!)
if "主演" in film_author_actor and len(re.findall('\\xa0主演: (.*)',film_author_actor))==1:
film_actor_test = re.findall('\\xa0主演: (.*)',film_author_actor)[0].strip()
film_actor = re.sub('\\xa0','',film_actor_test)
else:
film_actor = "空"
# 电影分类 注意:分类信息中有些不必要的空格,通过re中的sub方法删除!
film_category_test = film_one.xpath("./div[2]/p/text()")[1].strip()
film_category = re.sub('\\xa0','',film_category_test)
# 电影评分
film_score = film_one.xpath("./div[2]/div/span[2]/text()")[0]
# 将数据放入字典!
film_info["film_name"] = film_name
film_info["film_author"] = film_author
film_info["film_actor"] = film_actor
film_info["film_category"] = film_category
film_info["film_score"] = film_score
# 序列化的过程:将字典格式转为json格式
content = json.dumps(film_info,ensure_ascii=False) + "," + "\n"
f.write(content)
for i in range(9):
films(i*25)
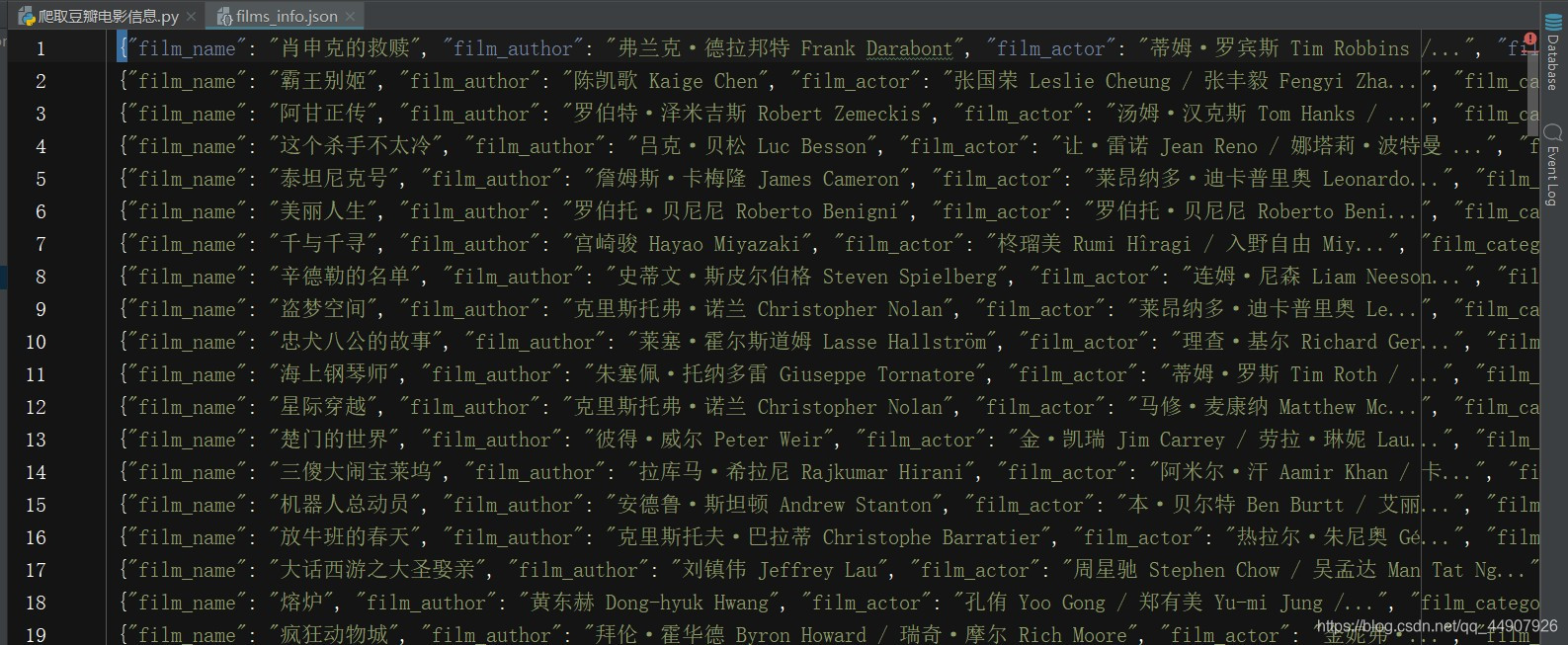
3.实现效果:可以完整正确无误的获取豆瓣Top250中的所有250部电影的目标信息!
第二部分:配合使用多线程提高效率!!!
标签:爬虫实战 python
精华推荐