
【Python爬虫实战】知乎热榜数据采集,上班工作摸鱼两不误,知乎热门信息一网打尽
日期: 2021-06-23 分类: 个人收藏 973次阅读
目录
爬取目标
网址:知乎热榜 
工具使用
开发环境:win10、python3.7 开发工具:pycharm、Chrome 工具包:requests,lxml, re
项目思路解析
对目标网址发送网络请求 获取到网页数据 提取到标题数据 
提取图片地址 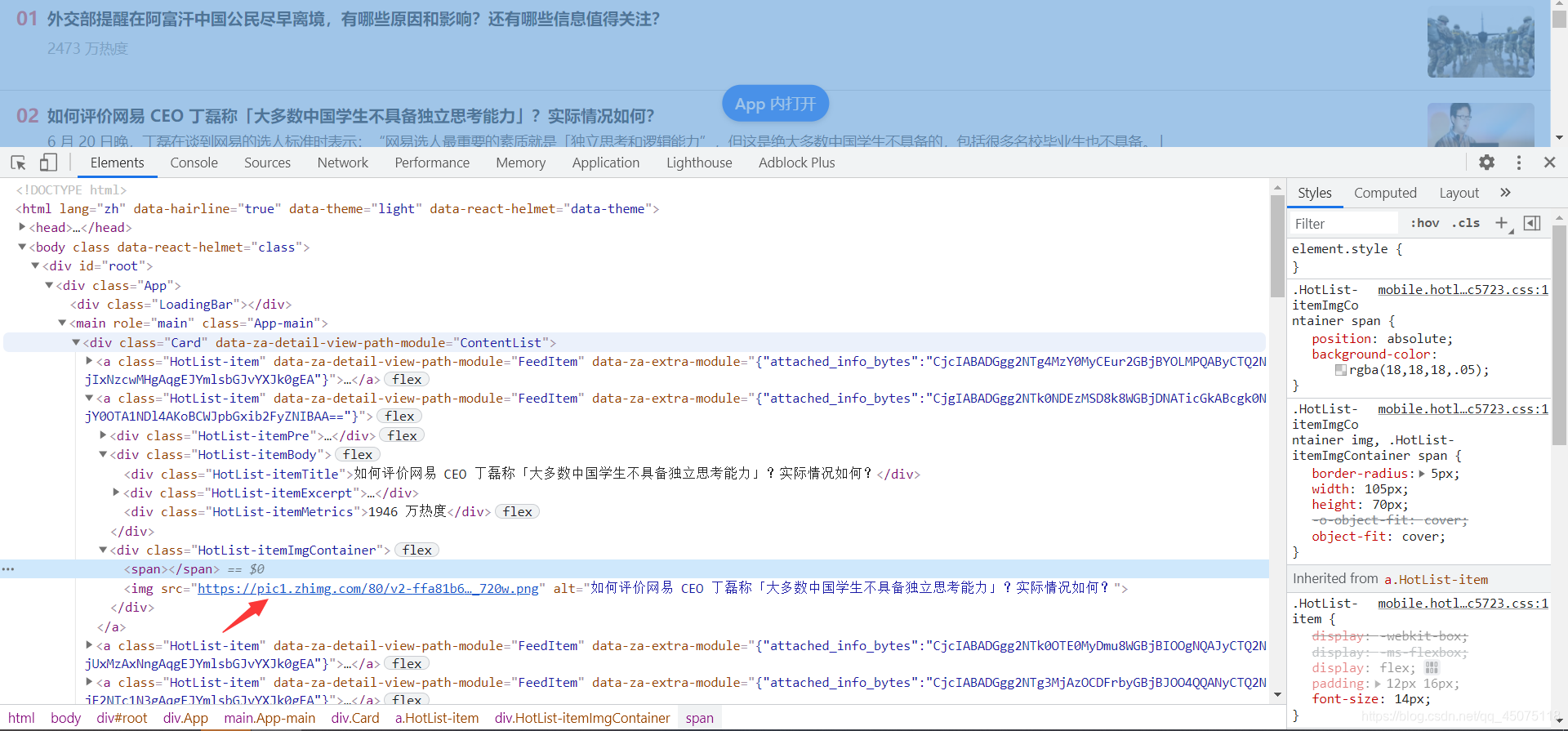 获取详情内容地址 详情地址并不在a标签内 正则提取详情页面地址
获取详情内容地址 详情地址并不在a标签内 正则提取详情页面地址  详情url需要进行分割替换
详情url需要进行分割替换
简易源码分享
import re # 正则表达式
import requests # 发送网络请求
from lxml import etree # 转换数据的
# 同意资源定位符
url = 'https://www.zhihu.com/billboard'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
}
# 发送网络请求
response = requests.get(url, headers=headers)
# print(response.text)
# 提取数据 xpath方式 提取数据 正则 bs4
new_url_list = re.findall('link":{"url":"(.*?)"}', response.text)
print(new_url_list)
html_object = etree.HTML(response.text)
a_list = html_object.xpath('//a[@class="HotList-item"]')
# print(a_list)
for a, new_url in zip(a_list, new_url_list):
title = a.xpath('.//div[@class="HotList-itemBody"]/div[1]/text()')[0]
url1 = new_url.replace('u002F', '')
img_url = a.xpath('./div[@class="HotList-itemImgContainer"]/img/@src')[0]
f = open('知乎热榜数据.text', "a", encoding='utf-8')
f.write("标题:" + title + '\n')
f.write("文章地址:" + url1 + '\n')
f.write("图片地址:" + img_url + "\n")
f.write("\n")
❀微信扫一扫关注公众号加入学习技术解答小天地+q裙:881744585【欢迎小哥哥。小姐姐】❀

除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐